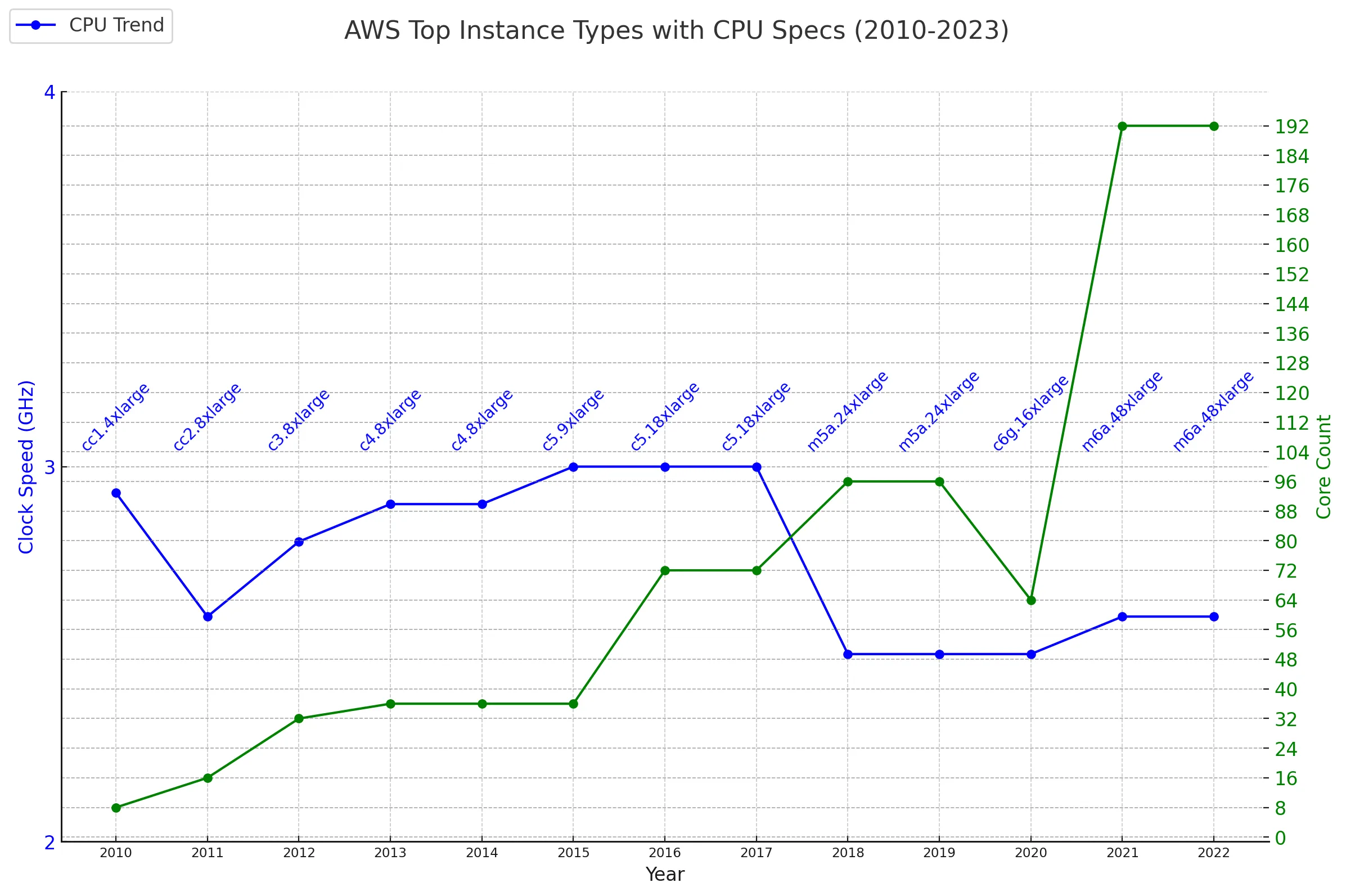
 可见整个半导体行业已经放弃提高 CPU 主频了,而是改为提高 CPU Core 的数量。
可见整个半导体行业已经放弃提高 CPU 主频了,而是改为提高 CPU Core 的数量。
SMP: 共享内存,所有处理器访问内存的速度一致。
NUMA: 分布式内存,处理器访问本地内存快,访问远程内存慢。
SMP: 扩展性有限,处理器数量增加会导致锁竞争和性能瓶颈。
NUMA: 高扩展性,适用于大型系统,处理器数量增加不会显著影响性能。
如果你把 Cloud 看做一整台计算机,那么不同 EC2 之间可以理解为不同的 NUMA Node。Cloud Function 更可以看成一个更小单位的 NUMA Node。从这个角度来看, 对等的直接访问别的 NUMA Node 的内存更加是不可能的,所以只能通过跨网络发消息。
换个角度,如果我们不在 Core 之间做任何的资源 Sharing, 或者是说把他们作为独立的计算机来使用会怎么样呢?简单的说就是下面的描述
无锁架构
通过消息显示共享
我们首先就可以收获到完全没有锁的代码,在所有的代码里都没有锁,会大幅度降低编码的难度,调试的难度,以及提高吞吐量等性能参数。在极少需要的情况下,通过 message-passing 来跨 core 发送数据。
如果你面对的计算机不是在单主板上的 NUMA 计算机,而是用网络相连的 Cloud 呢?Shared-Nothing 是唯一的办法,如果你依赖于 SMP 的架构,那么你要为使用的不同资源使用不同的架构。
比如下面几种情况:
只有单台超强的计算机,比如 单台 192 core 的 m6a.48xlarge
多个 Cloud Function,分布在不同的物理服务器上的很多临时产生的 cloud function。
多台计算机(可以是物理机,也可以是虚拟机),通过网络连接的多台计算机,他们可能性能并不完全一样。
多台计算机和多个 Cloud Function,可以理解为 上面的情况的特殊情况,不过 Cloud Function 能力较弱,生命周期较短。
用 Shared-Nothing 架构都可以适应。
如果你觉得 cpu 还是一切的中心,那么可以看看下面的内容,世界已经发生了天翻地覆的改变。
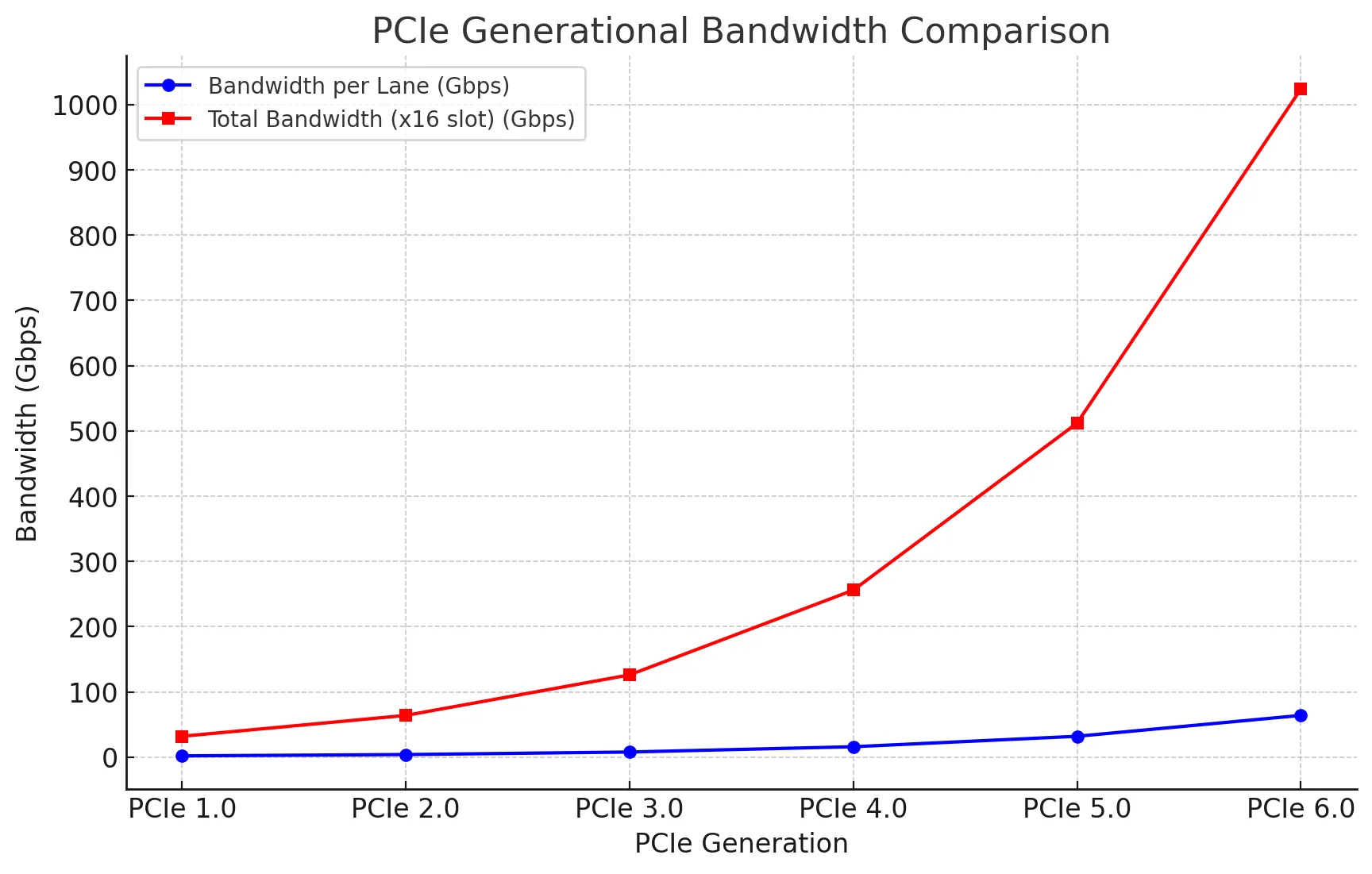
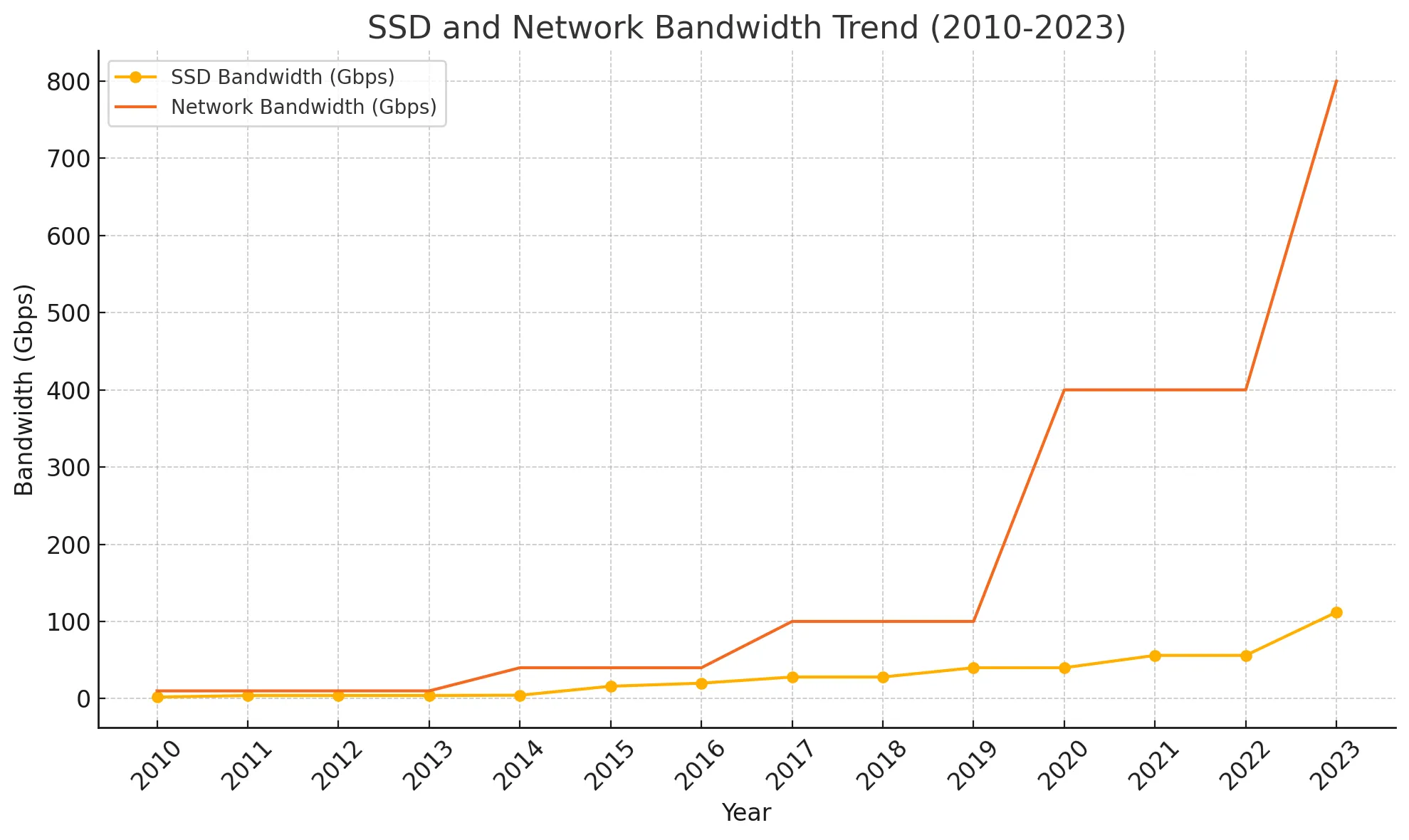 而且服务器是可以配置更多的网卡或者 SSD 磁盘的,就会几倍的放大上面的增量,瓶颈在于总线带宽。下面是 PCIe 总线的带宽变化图。
而且服务器是可以配置更多的网卡或者 SSD 磁盘的,就会几倍的放大上面的增量,瓶颈在于总线带宽。下面是 PCIe 总线的带宽变化图。
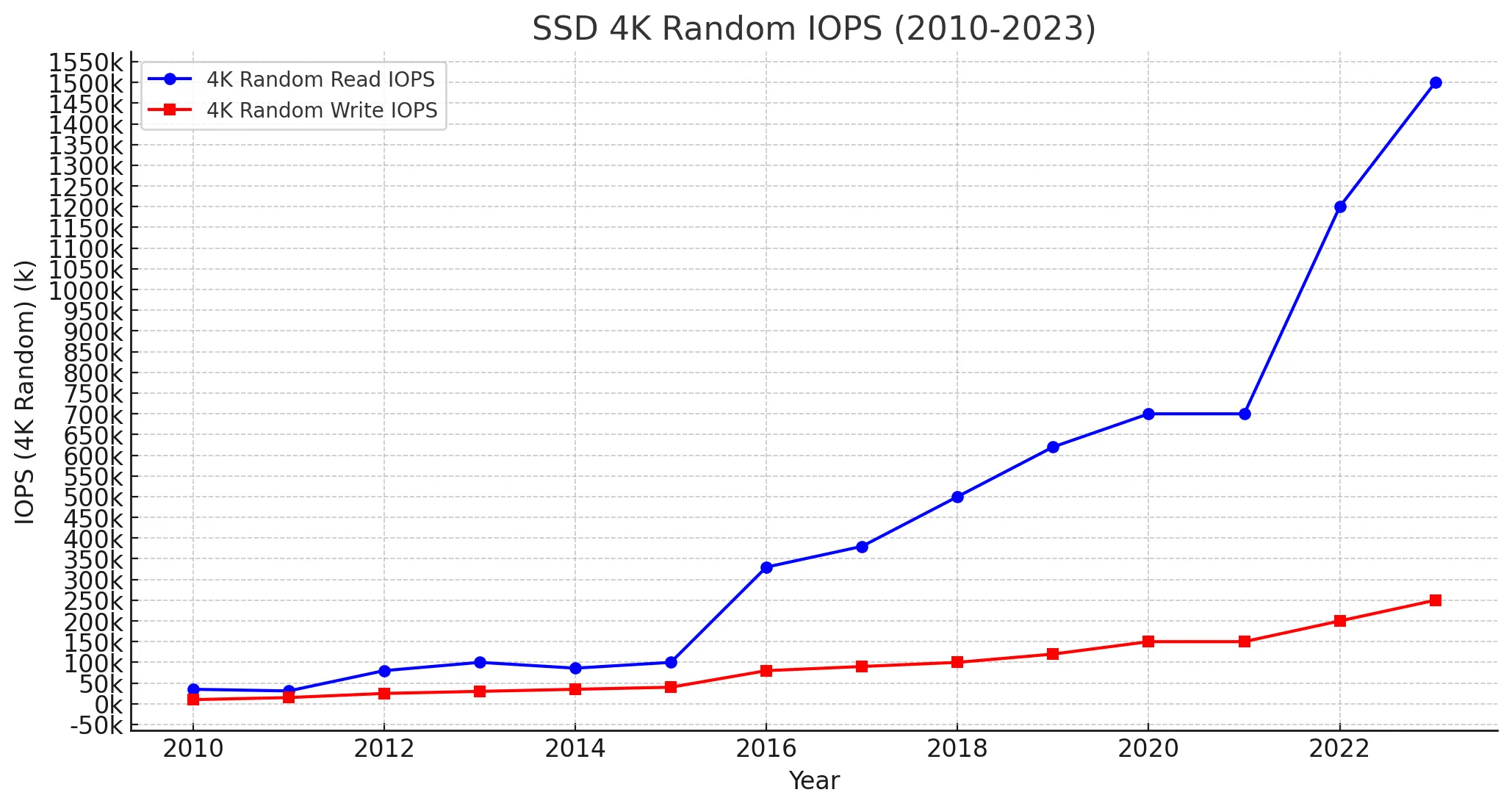
 下面是历年发布的 单块 SSD 的 iops 的变化
下面是历年发布的 单块 SSD 的 iops 的变化
 我们知道在传统上 IO 非常慢,都是由 OS kernel 来负责处理,linux 在问世后的30 年里,几乎一直是这么工作的,linux epoll 问世后,Application 通过异步的方式访问网络 IO 带来了巨大的性能提升,但是当 网络带宽到 40G 以上,epoll 就不够处理完所有的网络包了,因为协议栈的成本,内核里大量的锁等原因,当磁盘达到 pcie4 以后,当写入或者读取达到一个足够大的值以后,磁盘 io 的协议栈也会打满 cpu,当 IO 大幅度增长以后, cpu 成了瓶颈(原因在于锁争用)。
我们知道在传统上 IO 非常慢,都是由 OS kernel 来负责处理,linux 在问世后的30 年里,几乎一直是这么工作的,linux epoll 问世后,Application 通过异步的方式访问网络 IO 带来了巨大的性能提升,但是当 网络带宽到 40G 以上,epoll 就不够处理完所有的网络包了,因为协议栈的成本,内核里大量的锁等原因,当磁盘达到 pcie4 以后,当写入或者读取达到一个足够大的值以后,磁盘 io 的协议栈也会打满 cpu,当 IO 大幅度增长以后, cpu 成了瓶颈(原因在于锁争用)。
我们前面刚刚介绍了 CPU 发展的趋势。cpu 的单核主频是基本不变的,但是 core 数增加。
在这种硬件发展趋势的影响下,我们就得到了如下 2 个原则:
要尽量发挥出 IO 协议栈的潜力。
在各种场景里尽量用 IO 换 CPU。
但是要做到这两个原则,其实都非常难,因为这都涉及到从基础库到数据结构到算法的设计倾向的改变。
在新一代高性能服务器上,将 IO Stack 搬运到用户态,并且将所有关于 IO 的代码异步化就是关键。如果一个 IO 基础库不是异步的,它就不能用。而数据结构可以比传统的 size 大一些,但是不能占用太大的 cpu 处理时间,比如解压/解码/扫描等。而算法上,降低 cpu 压力,而不是加大 cpu 压力是适配这种技术发展趋势的必然选择。
nvme ssd 的发展还在压着 PCIe 的边界,1.6Tbps 的网卡已经设计出来,预计未来几年也会得到部署。也就是说,今天 cpu 和 IO 的差距还会进一步放大。如果你今天的设计就已经让 cpu 成为了瓶颈,那么在未来,同样的软件跑在更新的硬件上就会浪费新增长的 IO 能力。
per core per stack 设计,把单个 Cpu core 看做一台完整的计算机。
fully-async code,传统上 linux 上的磁盘读写都是同步的, 如果遇到高性能的 IO 硬件会造成大量浪费。所以我们用异步的方式重写了和 IO 有关的所有代码
尽量避免类似列式存储这样的存储格式,因为它重度依赖 CPU 能力。总会打满 CPU 和 Memory Bandwidth。而是使用重 IO,轻 CPU 的数据格式。
适配 DPDK 和 SPDK,允许用户通过使用他们来发挥超高端硬件配置服务器的性能(企业版)。
自由部署于多种云上硬件上。充分利用弹性。甚至可以工作在异构的硬件上。
完全无锁设计,从来不会因为有锁争用甚至死锁/活锁的事情发生,也无需为此类问题进行调试。
当使用现代的高性能硬件时,稳定低延迟、高吞吐(未来几篇文章会提供 benchmark 的代码和数据集),而且延时稳定。
当使用云上的 Cloud Function 作为底层硬件时,使用成本非常低廉。
因为利用 IO,所以基于同样的硬件 ClapDB 同时可以提供服务的 QPS 远远超过基于列存储的数据仓库。
服务于同样的 workload 时,成本很低,考虑到未来 IO 的发展,未来会更便宜。这是为了未来而生的架构设计。