如果你是 IT 行业从业者,我相信你心目里一个数据库应有的样子是长期运行在单台服务器里的一个(或者多个)驻守进程。它一般会长期占据大量的服务器资源。在分布式系统里,我们会通过某种方案来将多个独立的数据库服务组成一个集群,来实现 High available,或者 sharding。这种数据库我们可以统称为单机数据库。
即使现在有很多数据库号称分布式,但是其实也就是通过 proxy 的方式将多个单机数据库组成某种集群的方式来实现。
他们的架构图一般是下面的样子:
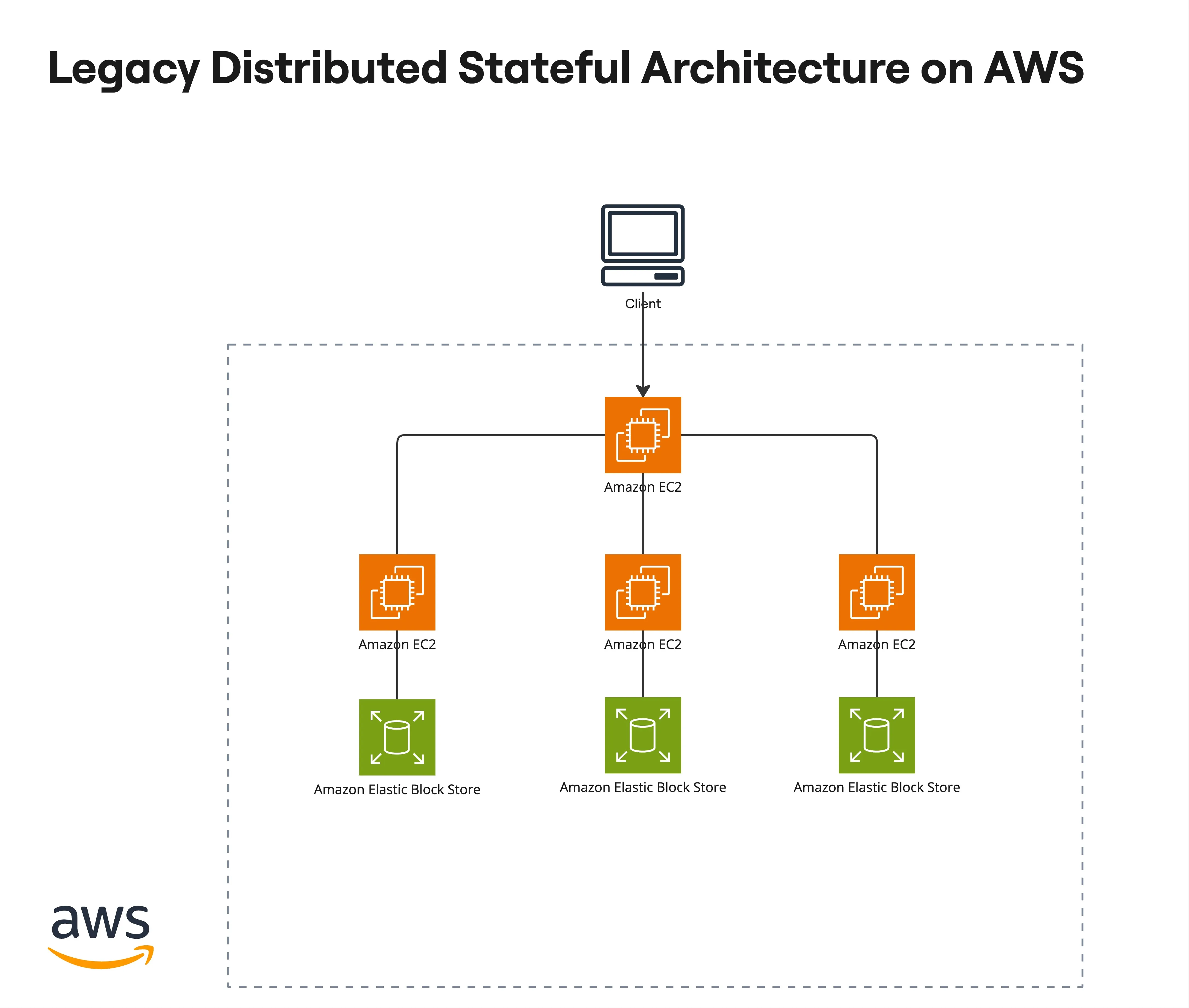 或者是下面的样子:
或者是下面的样子:
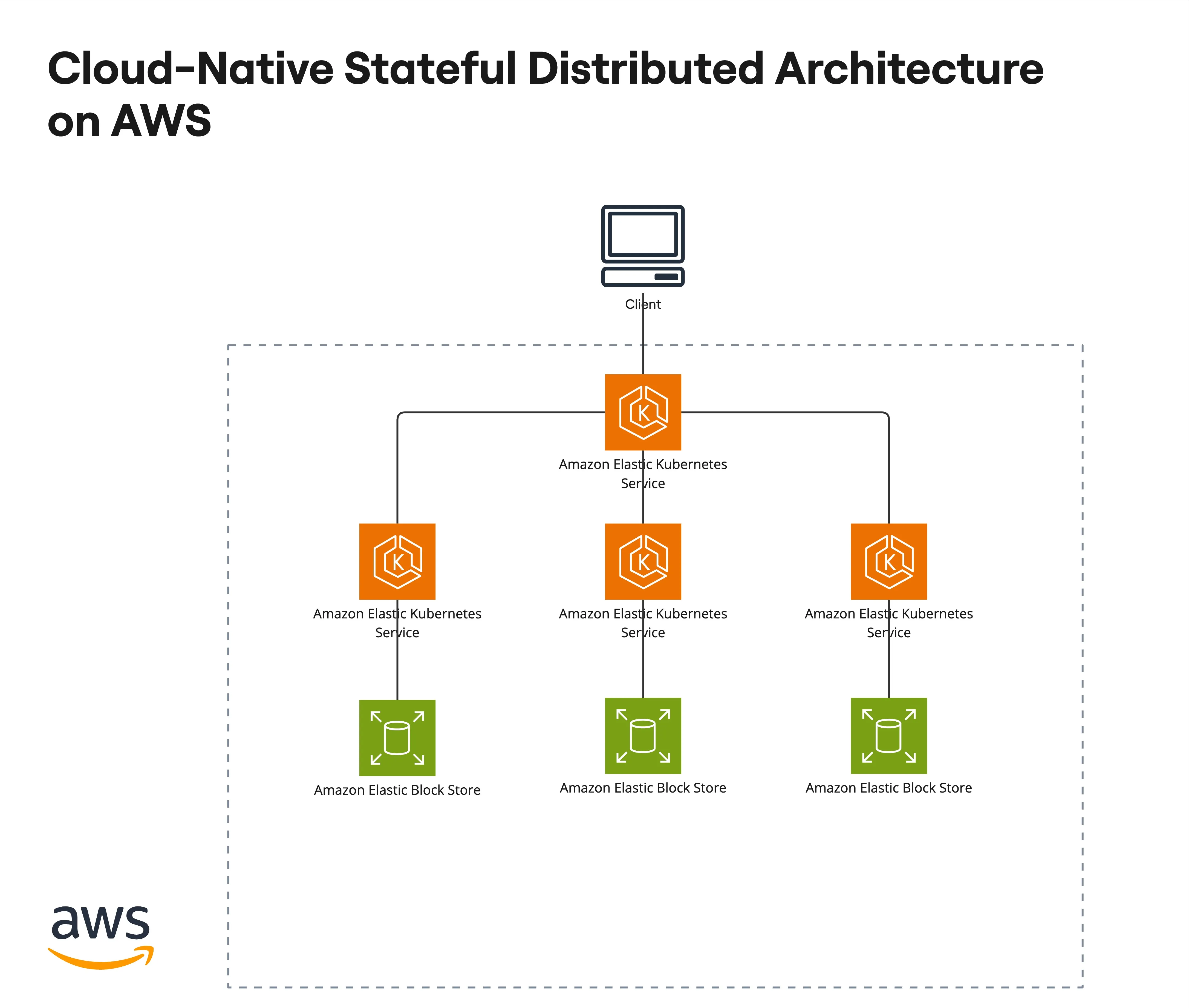 而 ClapDB 和所有单机数据库完全不同,它的不同组件分别部署于 cloud function 或者 VM 里。在 AWS 上它直接使用 api gateway、sqs、s3、lambda、EC2、iam、kms 等云服务来完成数据库的功能。
而 ClapDB 和所有单机数据库完全不同,它的不同组件分别部署于 cloud function 或者 VM 里。在 AWS 上它直接使用 api gateway、sqs、s3、lambda、EC2、iam、kms 等云服务来完成数据库的功能。
ClapDB 的架构图如下:
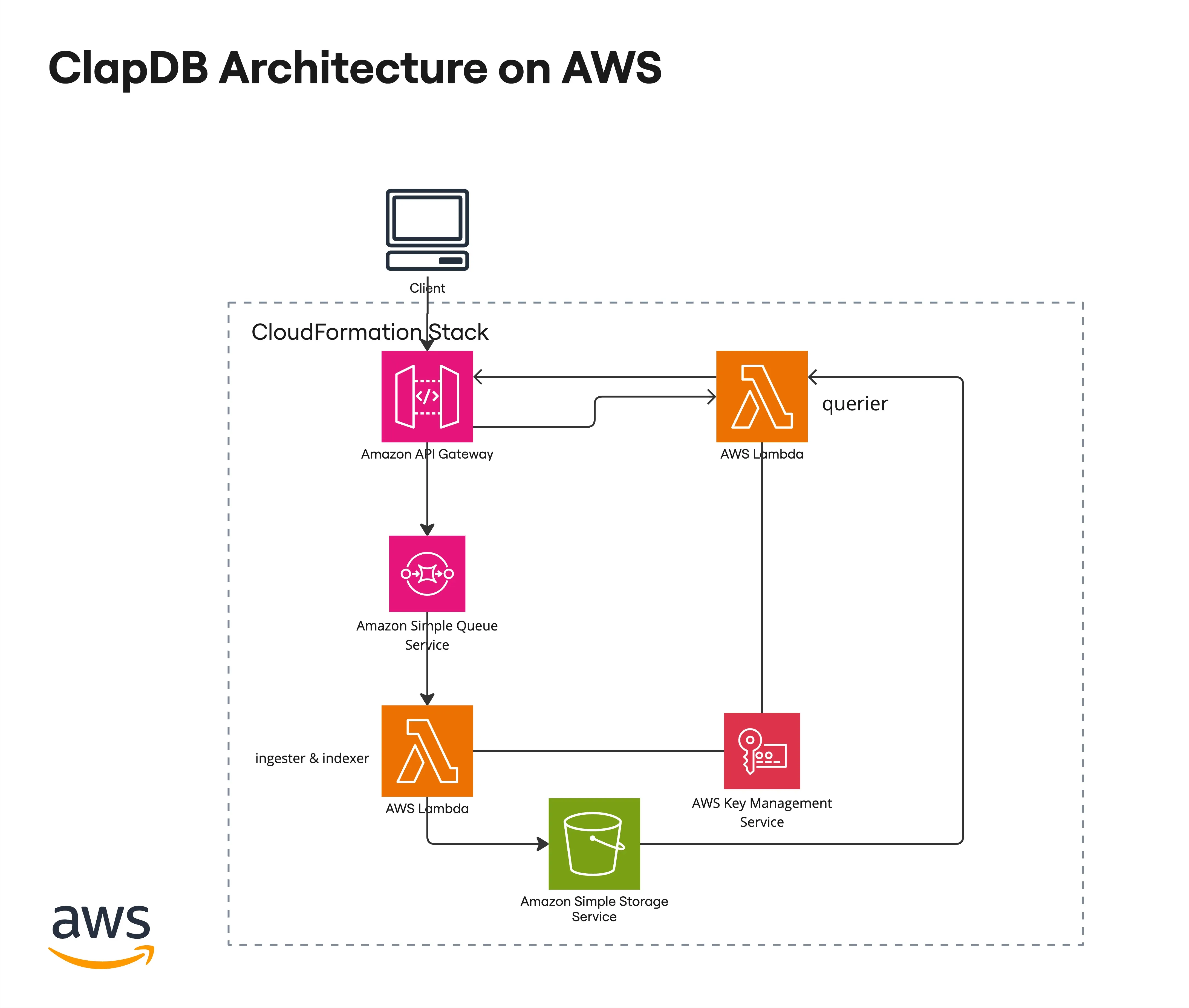
ClapDB 的设计出发点就和传统的数据库或者数据仓库完全不同,ClapDB 是以云作为操作系统都视角来设计架构的,而不是把云看成服务器集群。这里面有很多根本的设计取舍。详细的讲解请参看我们的文章:云是一台新的计算机。
这就要从我们开发 ClapDB 的初心讲起了。在 2020 年,我发现想找到一个合适的数据仓库是不可能的事情。绝大部分数仓有下面的问题:
Inflexible:竟然没有一种数据库实现好弹性,无论是写入,还是查询,都需要使用者根据需要实现做好容量规划,分配好硬件。拜托,AWS 上所有资源都用 Elastic 开头了,怎么还是云上 IDC2.0 啊?
High Operational Overhead: 开源数据库都极难运维,要想降低运维成本,就只能通过采购厂商提供的 managed service 来解决,但是这就带来了数据安全和合规问题。
Low concurrency: 几乎所有的分析服务就算用了很贵的硬件,所能提供的并发访问能力都极低,往往只有不到 10 个 QPS 的并发能力。
Single data model:每一种开源或者商业数据服务,往往都仅仅支持一种 data model,比如关系型、时序、全文检索、图等等。如果你的数据包含这些范式,你就要在上层代码里将数据库的查询结果 pull 回去,进行 aggregation 或者 join。巨大的带宽消耗,可能更巨大的内存和 cpu 消耗。
以上这些问题带来了巨大的开发成本、运维成本和资源账单。
我们之前的一系列文章针对上面问题,分别给出了解法:
Elastic:我们在 朋友,你真的知道如何利用“弹性”么?里讲解了如何发挥云的弹性,来适配不同的 workload,在 恕我直言,你的业务不配用服务器里我们介绍了使用 aws lambda 类似的 cloud function 来追求更极致的弹性和更高的性价比。
BYOC:我们在成年人不做选择,我要私有化部署的 SaaS 里讲解了如何利用 BYOC 技术来将运维成本降到 0,并且让用户可以将数据存储在自己的云账户中,满足数据安全和合规需求。
High Concurrency:基于云提供的弹性,以及资源隔离特性,我们可以充分利用云资源的弹性来为单机群提供并发,而且在资源使用上,我们在 摩尔定律已死,ClapDB 怎么办?里介绍了 CPU 的算力停滞多年,而网络 IO 和 磁盘 IO 一直在持续的高速增长。所以我们利用 IO 资源去绕过 CPU 算力的瓶颈。可以获得更稳定的延时以及更高的并发能力。
Multi-data model:直接说结果,ClapDB 同时支持 relational、time-series、full-text search、document、vector、graph、geo 等多种 data model。也就是说,用户可以将自己的所有数据存储于 ClapDB 一个分析服务中,通过 ClapDB 完成对多种 data model 的 aggregation 和 join。
并且在云上,我们利用云提供的组件作为核心系统的载体,具体思路参看 名为“原生”,实则“排异”——有状态服务请对云原生say no 一文。通过这个方法,我们几乎彻底的提高了整个系统的 scalability 和 availablity。
那么上面这些 Features 带来了什么和过去的数据库完全不同的表现呢?
使用同一份数据,只需要调整使用的算力和存储的规格,就可以在低成本和低延时之间平衡。用户可以指定哪些数据需要更低延时的实时查询,哪些数据不需要。
同一个服务,能够提供任何结构化和半结构化数据模型的存储和查询。
因为基于存算分离,算算隔离,读写分离,可以几乎无限的提高写入 throughput,或者提高查询的 QPS。
BYOC,且无人值守,因为就算出错也只会影响单个查询,并不会影响整个系统。
我们在 摩尔定律已死,ClapDB 怎么办?一文里提过:
网络和磁盘 IO 都在持续的快速发展:提高性能,降低成本。
CPU 受限于物理极限,单核性能不再增长,核数越来越多,并且已经走向了节能的方向。
ClapDB 为了适应硬件趋势,做了和之前产品完全不同的架构设计:
解开系统和软件的限制,发挥 IO 的潜力。
shared-nothing 架构,全局无锁设计,避免 SMP 架构下锁争用,内存总线争用,Cacheline 污染 问题。彻底释放多核的威力。
在拥有高性能网络或者高性能 NVME 磁盘的机器上, ClapDB 都能发挥出最好的表现。而且随着未来几代硬件在这几个方面的继续提升,ClapDB 和之前的上一代或者上两代产品的之间的差距会越来越大。
身处数据库/数据仓库行业,Benchmark 基本是必须的, 即使 benchmark 具有很大的误导性和局限性。但是我们还是尽量的诚实公平的设置 benchmark 环境和条件来展示一下 ClapDB 的能力。
篇幅所限(微信公众号文章不宜太长),具体的 Benchmark 数据和详细介绍请关注我们后续的文章。